library(askpass)
library(brandr)
library(beepr)
library(curl)
library(dplyr)
library(fs)
library(geobr)
library(geocodebr)
library(ggplot2)
library(googlesheets4)
library(here)
library(htmltools)
library(labelled)
library(lockr) # github.com/danielvartan/lockr
library(lubridate)
library(magrittr)
library(nanoparquet)
library(orbis) # github.com/danielvartan/orbis
library(osfr)
library(purrr)
library(readr)
library(rvest)
library(rutils) # github.com/danielvartan/rutils
library(sf)
library(stringr)
library(tidyr)
library(vroom)
library(zip)A Reproducible Pipeline for Processing, Geocoding, and Classifying CNPJs From the Annual Social Information Report (RAIS) of the Brazilian Ministry of Labor and Employment (MTE) Using the Locais-Nova Scale

![]()
![]()
![]()
Overview
This report provides a reproducible pipeline for processing, geocoding, and classifying CNPJs from the Brazilian Annual Social Information Report (RAIS) of the Brazilian Ministry of Labor and Employment (MTE) using the Locais-Nova scale.
For instructions on how to run the pipeline, see the repository README.
Problem
The AcessoSAN project aims to develop methods for measuring and analyzing inequities in access to healthy food in favelas and other urban communities. Achieving this requires a reliable and up-to-date database of food establishments.
The Brazilian Annual Social Information Report (RAIS) database of the Brazilian Ministry of Labor and Employment (MTE) lists companies operating in Brazil, including food establishments. However, it does not provide geocoded information, which is required for spatial analyses. This pipeline addresses that gap by processing and geocoding the data, and classifying establishments according to the Locais-Nova scale.
Data Availability
![]()
The processed data are available in csv, rds and parquet formats through a dedicated repository on the Open Science Framework (OSF). A metadata file is included alongside the validated datasets.
Because the raw data are not publicly available, only authorized personnel can access the processed files. They are protected with RSA 4096-bit encryption (OpenSSL) and a 32-byte password to ensure data security.
If you already have access to the OSF repository and the project keys, click here to access the data. You can also retrieve these files directly from R using the osfr package.
Methods
Source of Data
The data used in this report come from the following sources:
- Brazilian Ministry of Labor and Employment (MTE): Data on food establishments from the Annual Social Information Report (RAIS) related to 2022, provided by request, used for company identification.
- Brazilian Federal Revenue Service (RFB): Data on legal entities from the National Register of Legal Entities (CNPJ).
- Brazilian Institute of Geography and Statistics (IBGE):
- Center for Metropolitan Studies (CEM): Lookup table providing the classification linking the establishments CNAEs (National Classification of Economic Activities) codes to the Locais-Nova groups. This data will remain private until further notice.
Data Munging
The data munging follow the data science workflow outlined by Wickham et al. (2023), as illustrated in Figure 1. All processes were made using the Quarto publishing system, along with the AWK (Aho et al., 2023) and R (R Core Team, n.d.) programming languages, supported by several R packages.
For data manipulation and workflow, priority was given to packages from the tidyverse, rOpenSci and r-spatial ecosystems, as well as other packages adhering to the tidy tools manifesto (Wickham, 2023).
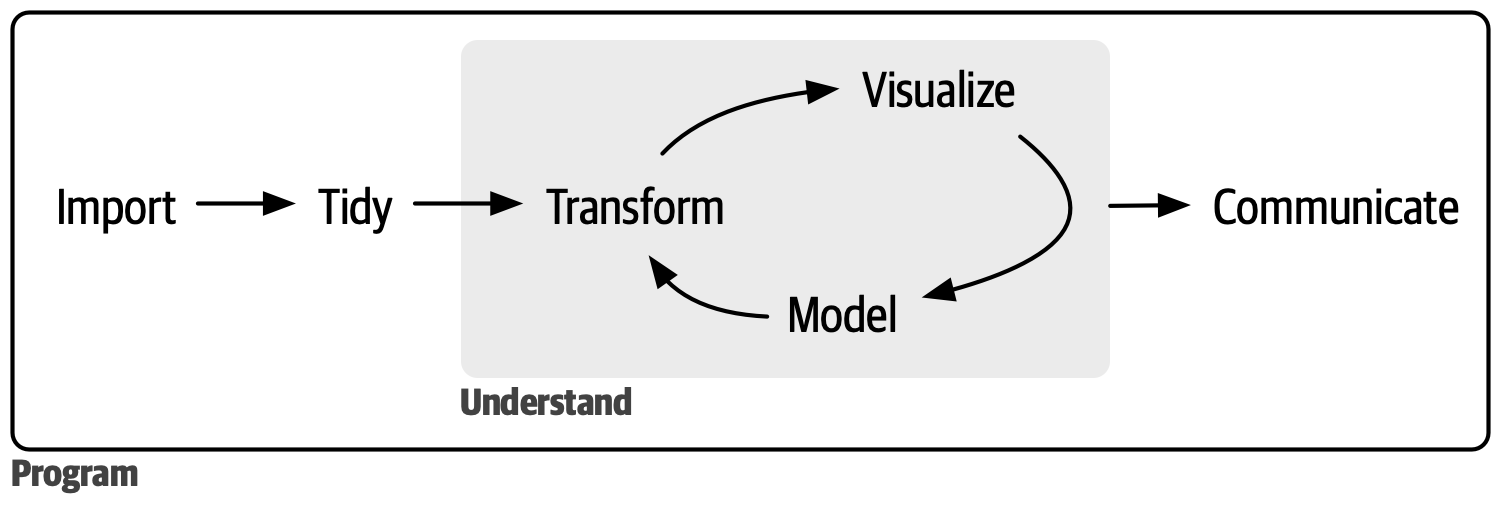
Source: Reproduced from Wickham et al. (2023).
Code Style
The Tidyverse code style guide and design principles were followed to ensure consistency and enhance readability.
Reproducibility
The pipeline is fully reproducible and can be run again at any time. To ensure consistent results, the renv package (Ushey & Wickham, n.d.) is used to manage and restore the R environment. See the README file in the code repository to learn how to run it.
Set the Environment
This section sets up the R environment needed for the workflow.
Load Packages
Set Keys
See the Data Availability section for more information.
osf_auth(Sys.getenv("OSF_PAT")) # askpass())gs4_auth(cache = ".secrets")public_key <- here("_ssh", "id_rsa.pub")private_key <- here("_ssh", "id_rsa")password <- Sys.getenv("ACESSOSAN_PASSWORD") # askpass()Set Input and Output Paths
for (i in c(raw_data_dir, data_dir)) {
if (!dir_exists(i)) dir_create(i, recurse = TRUE)
}Set Initial Variables
These variables specify which consolidated RFB dataset to use and which municipalities to process.
set.seed(2025)year <- 2025month <- 1municipalities <- c( # IBGE Codes
1721000, # Palmas
2507507, # João Pessoa
3106200, # Belo Horizonte
3550308, # São Paulo
4314902, # Porto Alegre
5208707, # Goiânia
5300108 # Brasília
)Download Locais-Nova CNAE Lookup Table
See the Source of Data section for more information.
lookup_data <-
read_sheet(
ss = "1ipCw2FM3aUOdRd4w55J5SUEgXDCogxWZF-NZi0A-o_4",
sheet = "Dataset"
) |>
mutate(
g0 = if_else(
g1_g2 == TRUE & g3 == FALSE & g4 == FALSE,
TRUE,
FALSE
)
)
#> Auto-refreshing stale OAuth token.
#> ✔ Reading from "Locais-Nova By CNAE".
#> ✔ Range ''Dataset''.lookup_data |> glimpse()
#> Rows: 540
#> Columns: 7
#> $ cnae <chr> "4711302", "5611201", "4722902", "4721102", "4721101",…
#> $ description <chr> "Supermarket 1", "Restaurant", "Fish Market", "Bakery …
#> $ federal_unit <chr> "AC", "AC", "AC", "AC", "AC", "AC", "AC", "AC", "AC", …
#> $ g0 <lgl> FALSE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ g1_g2 <lgl> TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, F…
#> $ g3 <lgl> FALSE, FALSE, FALSE, TRUE, TRUE, FALSE, FALSE, TRUE, F…
#> $ g4 <lgl> TRUE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE…Download Agencies and Municipalities (TOM) Data
See the Source of Data section for more information.
url <- "https://www.gov.br/receitafederal/dados/municipios.csv"curl_download(url, destfile = file.path(raw_data_dir, "municipios.csv"))Download and Import IBGE Municipalities Data
See the Source of Data section for more information.
municipalities_data <- brazil_municipality(year = year)
#> ! The closest map year to 2025 is 2022. Using year 2022 instead.
#> Using year/date 2022municipalities_data |> glimpse()
#> Rows: 5,570
#> Columns: 9
#> $ region_code <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
#> $ region <chr> "North", "North", "North", "North", "North", "Nor…
#> $ state_code <int> 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 1…
#> $ state <chr> "Rondônia", "Rondônia", "Rondônia", "Rondônia", "…
#> $ federal_unit <chr> "RO", "RO", "RO", "RO", "RO", "RO", "RO", "RO", "…
#> $ municipality_code <dbl> 1100015, 1100023, 1100031, 1100049, 1100056, 1100…
#> $ municipality <chr> "Alta Floresta D'Oeste", "Ariquemes", "Cabixi", "…
#> $ latitude <dbl> -11.935540305, -9.908462867, -13.499763460, -11.4…
#> $ longitude <dbl> -61.99982390, -63.03326928, -60.54431358, -61.442…Download RAIS Data
See the Source of Data section for more information.
Download File
osf_raw_data_id <- "tdswp"osf_raw_data_files <-
osf_raw_data_id |>
osf_retrieve_node() |>
osf_ls_files(
type = "file",
pattern = "rais_alim_",
n_max = Inf
)
osf_raw_data_filesrais_file <-
osf_raw_data_files |>
osf_download(path = raw_data_dir, conflicts = "overwrite") |>
extract2("local_path")Unlock File
rais_file |>
unlock_file(
private_key = private_key,
suffix = ".lockr",
remove_file = TRUE,
password = password
)Download RFB Data
See the Source of Data section for more information.
Download Files
root <- file.path( # Don´t change the function!
"https://arquivos.receitafederal.gov.br",
"dados",
"cnpj",
"dados_abertos_cnpj"
)path <- root |> file.path(paste0("2025-", str_pad(month, 2, pad = 0)))
urls <-
path |>
read_html() |>
html_elements("a") |>
html_attr("href") |>
str_subset("\\.zip$") %>%
file.path(path, .)urls |>
map_dbl(.f = get_file_size, .progress = TRUE) |>
sum() |>
as_fs_bytes()
#> 6.26Gurls |> download_file(dir = raw_data_dir)Unzip Files
zip_files <- raw_data_dir |> dir_ls(type = "file", regexp = "\\.zip$")zip_files |> file_delete()Import Agencies and Municipalities (TOM) Data
RFB data identifies municipalities using a different coding scheme (Tabela de Órgãos e Municípios, TOM) than IBGE codes. Mapping IBGE codes to the corresponding TOM codes is therefore required.
municipalities_tom_data <-
raw_data_dir |>
path("municipios.csv") |>
read_delim(
delim = ";",
col_names = FALSE,
col_types = cols(.default = "c"),
progress = FALSE
) |>
slice(-1) |>
mutate(
across(
.cols = everything(),
.fns = \(x) iconv(x, from = "Windows-1252", to = "UTF-8") # iconvlist()
)
) |>
rename_with(
\(x) c(
"municipality_code_tom",
"municipality_code_ibge",
"municipality_tom",
"municipality_ibge",
"uf"
)
) |>
mutate(
municipality_code_tom = as.integer(municipality_code_tom),
municipality_code_ibge = as.integer(municipality_code_ibge)
)municipalities_tom_data |> glimpse()
#> Rows: 5,571
#> Columns: 5
#> $ municipality_code_tom <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 1…
#> $ municipality_code_ibge <int> 1100106, 1100379, 1100205, 1100452, 1100122,…
#> $ municipality_tom <chr> "GUAJARÁ-MIRIM", "ALTO ALEGRE DOS PARECIS", …
#> $ municipality_ibge <chr> "Guajará-Mirim", "Alto Alegre dos Parecis", …
#> $ uf <chr> "RO", "RO", "RO", "RO", "RO", "RO", "RO", "R…Import Data
establishment_data <-
raw_data_dir |>
path("rais_alim_2022.parquet") |>
read_parquet()establishment_data |> glimpse()
#> Rows: 731,497
#> Columns: 30
#> $ X <int> 10, 17, 27, 31, 80, 85, 91, 103, 111, 119,…
#> $ nu_cei_vinculado <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ nu_cep_estab <int> 6755185, 76650000, 95880000, 35600000, 790…
#> $ co_cnae95_classe <int> 52248, 55212, 55247, 52124, 55212, 52132, …
#> $ nu_cnpj_cei <dbl> 5046455000161, 30119065000111, 15393330000…
#> $ nu_cnpj_raiz <int> 5046455, 30119065, 15393330, 2508004, 2756…
#> $ dt_abertura <chr> "2002-04-19", "2018-04-05", "2012-04-16", …
#> $ dt_baixa <chr> "", "", "", "", "2019-09-26", "2023-08-01"…
#> $ dt_encerramento <chr> "", "", "", "", "2019-09-26", "2023-08-01"…
#> $ ds_email_estab <chr> "", "", "", "", "", "", "", "", "", "", ""…
#> $ in_cei_vinculado <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ id_estab_participa_pat <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ in_rais_negativa <int> 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, …
#> $ in_simples <int> 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, …
#> $ co_municipio <int> 355280, 521056, 430780, 310740, 500270, 41…
#> $ co_natureza_juridica <int> 2062, 2135, 2135, 2062, 2135, 2062, 2062, …
#> $ no_logradouro <chr> "R SANTO ONOFRE 200 TERREO.", "R 01 SN QUA…
#> $ nu_logradouro <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ no_bairro <chr> "JARDIM SANTA ROSA", "RESIDENCIAL BENEDITO…
#> $ nu_tel_empresa <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ qt_vinculos_ativos <int> 21, 0, 0, 1, 4, 0, 0, 4, 2, 0, 93, 4, 6, 1…
#> $ qt_vinculos_clt <int> 21, 0, 0, 1, 4, 0, 0, 4, 2, 0, 93, 4, 6, 1…
#> $ qt_vinculos_estatutarios <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
#> $ no_razao_social <chr> "ANSERVE COMERCIAL LTDA - ME", "0", "NÃO I…
#> $ in_tamanho_estab <int> 5, 1, 1, 2, 2, 1, 1, 2, 2, 1, 6, 2, 3, 2, …
#> $ tp_estabelecimento <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
#> $ co_ibge_subsetor <int> 16, 21, 13, 16, 21, 16, 21, 16, 16, 21, 16…
#> $ in_atividade_ano <int> 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, …
#> $ co_cnae20_classe <int> 47237, 56112, 56201, 47113, 56112, 47121, …
#> $ co_cnae20_subclasse <int> 4723700, 5611201, 5620104, 4711302, 561120…Filter Data
Only establishments with an Active registration status (in_atividade_ano == 9) and no negative records (in_rais_negativa == 0 | (in_rais_negativa == 1 & qt_vinculos_ativos > 0)) are retained. The data is then filtered by municipality, and duplicate CNPJs are removed.
The Locais-Nova lookup table is subsequently used to filter establishment data and classify establishments into the scale groups.
For more details on the Locais-Nova lookup table, see the Source of Data section.
establishment_data <-
establishment_data |>
select(
nu_cnpj_cei, dt_abertura, in_atividade_ano, in_rais_negativa,
co_municipio, qt_vinculos_ativos, in_atividade_ano, co_cnae20_subclasse
) |>
filter(
in_atividade_ano == 9 &
(in_rais_negativa == 0 | (in_rais_negativa == 1 & qt_vinculos_ativos > 0))
) |>
mutate(
cnpj = str_pad(as.character(nu_cnpj_cei), 14, pad = "0"),
cnae = str_pad(co_cnae20_subclasse, 7, pad = "0"),
registration_status_date = ymd(dt_abertura)
) |>
# distinct(cnpj, .keep_all = TRUE) |>
left_join(
municipalities_data |>
mutate(
municipality_code_6 =
municipality_code |>
str_sub(1, 6) |>
as.integer()
),
by = join_by(co_municipio == municipality_code_6)
) |>
filter(municipality_code %in% municipalities) |>
left_join(lookup_data, by = c("cnae", "federal_unit")) |>
rename(
locais_nova_g0 = g0,
locais_nova_g1_g2 = g1_g2,
locais_nova_g3 = g3,
locais_nova_g4 = g4
) |>
drop_na(starts_with("locais_nova")) |>
select(
cnpj, cnae, registration_status_date,
region_code, region, state_code, state, federal_unit,
municipality_code, municipality,
locais_nova_g0, locais_nova_g1_g2, locais_nova_g3, locais_nova_g4
)establishment_data |> glimpse()
#> Rows: 71,412
#> Columns: 14
#> $ cnpj <chr> "37278286000181", "38483830000351", "31275…
#> $ cnae <chr> "4721102", "4722901", "5611203", "5611201"…
#> $ registration_status_date <date> 2020-06-01, 2017-11-13, 2018-08-20, 2018-…
#> $ region_code <int> 3, 3, 3, 5, 3, 5, 4, 3, 3, 3, 3, 3, 3, 3, …
#> $ region <chr> "Southeast", "Southeast", "Southeast", "Ce…
#> $ state_code <int> 35, 31, 31, 53, 35, 53, 43, 35, 35, 35, 35…
#> $ state <chr> "São Paulo", "Minas Gerais", "Minas Gerais…
#> $ federal_unit <chr> "SP", "MG", "MG", "DF", "SP", "DF", "RS", …
#> $ municipality_code <dbl> 3550308, 3106200, 3106200, 5300108, 355030…
#> $ municipality <chr> "São Paulo", "Belo Horizonte", "Belo Horiz…
#> $ locais_nova_g0 <lgl> FALSE, TRUE, FALSE, TRUE, TRUE, TRUE, TRUE…
#> $ locais_nova_g1_g2 <lgl> FALSE, TRUE, FALSE, TRUE, TRUE, TRUE, TRUE…
#> $ locais_nova_g3 <lgl> TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, F…
#> $ locais_nova_g4 <lgl> FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, F…Visualize Registration Status Dates
These dates indicate when establishments were registered as Active.
establishment_data |>
ggplot(aes(x = registration_status_date)) +
geom_histogram(
bins = 30,
fill = get_brand_color("blue")
) +
scale_fill_brand_d() +
labs(
x = "Registration Status Date",
y = "Frequency"
)
#> Warning: Removed 22 rows containing non-finite outside the scale range
#> (`stat_bin()`).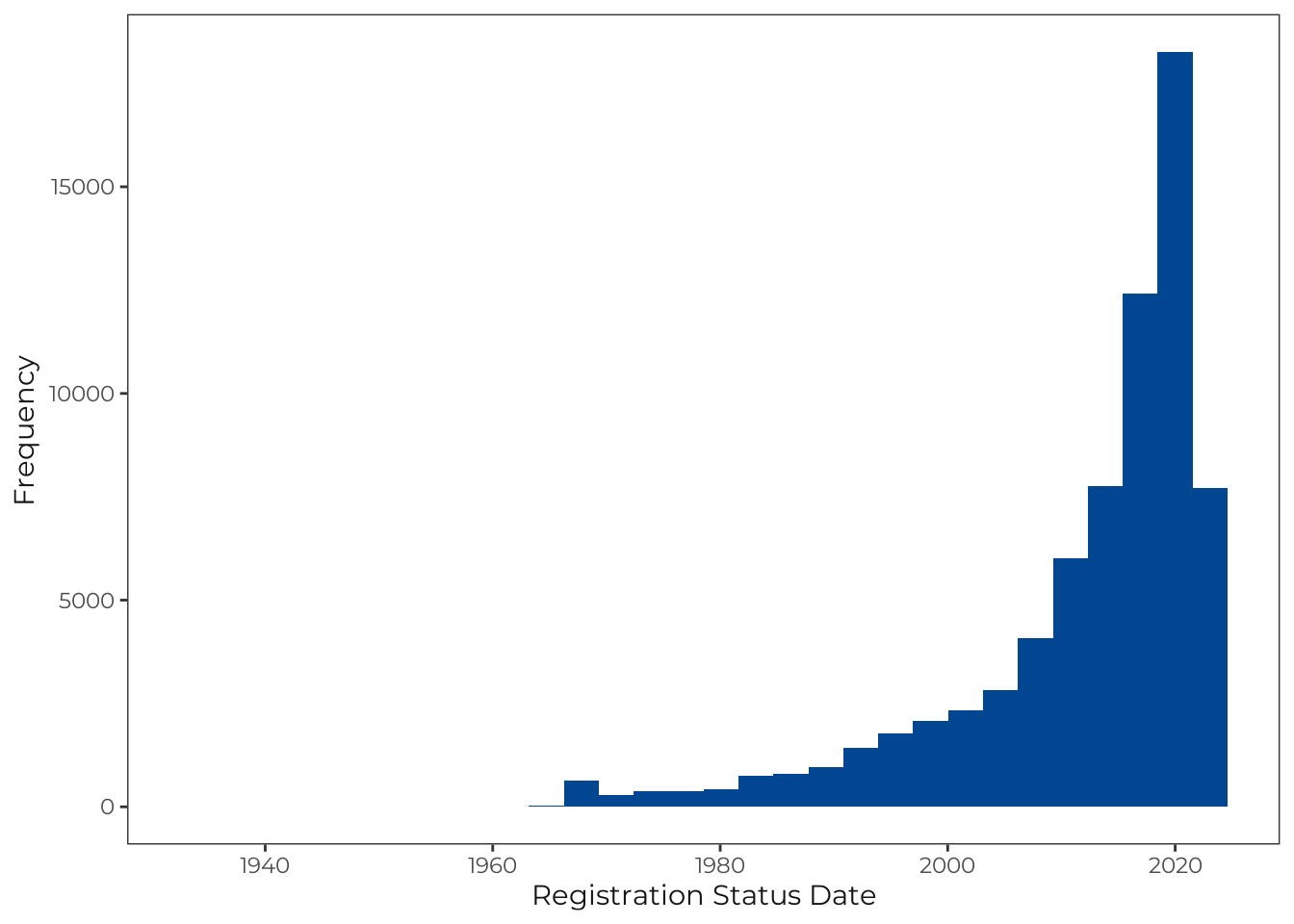
Tidy the Data
Some tidying operations are performed to ensure the data is in a suitable format for analysis.
establishment_data <-
establishment_data |>
mutate(
cnpj = if_else(
!is.na(cnpj),
paste0(
str_sub(cnpj, 1, 2),
".", str_sub(cnpj, 3, 5),
".", str_sub(cnpj, 6, 8),
"/", str_sub(cnpj, 9, 12),
"-", str_sub(cnpj, 13, 14)
),
NA_character_
),
cnae = if_else(
!is.na(cnae),
paste0(
str_sub(cnae, 1, 4),
"-", str_sub(cnae, 5, 5),
"/", str_sub(cnae, 6, 7)
),
NA_character_
),
municipality_code = as.integer(municipality_code)
) |>
select(-registration_status_date)establishment_data |> glimpse()
#> Rows: 71,412
#> Columns: 13
#> $ cnpj <chr> "37.278.286/0001-81", "38.483.830/0003-51", "31.2…
#> $ cnae <chr> "4721-1/02", "4722-9/01", "5611-2/03", "5611-2/01…
#> $ region_code <int> 3, 3, 3, 5, 3, 5, 4, 3, 3, 3, 3, 3, 3, 3, 5, 3, 5…
#> $ region <chr> "Southeast", "Southeast", "Southeast", "Central-W…
#> $ state_code <int> 35, 31, 31, 53, 35, 53, 43, 35, 35, 35, 35, 35, 3…
#> $ state <chr> "São Paulo", "Minas Gerais", "Minas Gerais", "Dis…
#> $ federal_unit <chr> "SP", "MG", "MG", "DF", "SP", "DF", "RS", "SP", "…
#> $ municipality_code <int> 3550308, 3106200, 3106200, 5300108, 3550308, 5300…
#> $ municipality <chr> "São Paulo", "Belo Horizonte", "Belo Horizonte", …
#> $ locais_nova_g0 <lgl> FALSE, TRUE, FALSE, TRUE, TRUE, TRUE, TRUE, TRUE,…
#> $ locais_nova_g1_g2 <lgl> FALSE, TRUE, FALSE, TRUE, TRUE, TRUE, TRUE, TRUE,…
#> $ locais_nova_g3 <lgl> TRUE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, F…
#> $ locais_nova_g4 <lgl> FALSE, FALSE, TRUE, FALSE, FALSE, FALSE, FALSE, F…Arrange the Data
The data is arranged by municipality code and CNAE.
establishment_data <-
establishment_data |>
arrange(municipality_code, cnae)establishment_data |> glimpse()
#> Rows: 71,412
#> Columns: 13
#> $ cnpj <chr> "75.315.333/0101-71", "75.315.333/0277-32", "04.4…
#> $ cnae <chr> "4711-3/01", "4711-3/01", "4711-3/01", "4711-3/01…
#> $ region_code <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
#> $ region <chr> "North", "North", "North", "North", "North", "Nor…
#> $ state_code <int> 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 1…
#> $ state <chr> "Tocantins", "Tocantins", "Tocantins", "Tocantins…
#> $ federal_unit <chr> "TO", "TO", "TO", "TO", "TO", "TO", "TO", "TO", "…
#> $ municipality_code <int> 1721000, 1721000, 1721000, 1721000, 1721000, 1721…
#> $ municipality <chr> "Palmas", "Palmas", "Palmas", "Palmas", "Palmas",…
#> $ locais_nova_g0 <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ locais_nova_g1_g2 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, T…
#> $ locais_nova_g3 <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ locais_nova_g4 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, T…Import RFB Data
The company addresses in the RAIS dataset are often incomplete; therefore, the CNPJs are cross-referenced with RFB data to obtain complete addresses.
The AWK programming language and the vroom R package are used to read and filter the data efficiently, without loading it entirely into memory.
Only establishments located within the specified municipalities are included, and any duplicate CNPJs are removed.
rfb_data <-
raw_data_dir |>
dir_ls(type = "file", regexp = "\\.ESTABELE$") |>
map(
function(x) {
vroom(
file = pipe(
paste0(
"awk ",
"-F ",
"';' ",
"'{ ",
"if (",
paste0(
'$21 == "\\"',
municipalities_tom_data |>
filter(municipality_code_ibge %in% municipalities) |>
pull(municipality_code_tom),
'\\""',
collapse = " || "
),
") ",
"print",
" }' ",
x
)
),
delim = ";",
col_names = c(
"cnpj_basic",
"cnpj_order",
"cnpj_dv",
"branch_identifier",
"trade_name",
"registration_status",
"registration_status_date",
"registration_status_reason",
"foreign_city_name",
"country",
"start_date",
"cnae_primary",
"cnae_secondary",
"street_type",
"street_name",
"number",
"address_complement",
"neighborhood",
"postal_code",
"federal_unit",
"municipality_code_tom",
"phone_area_code_1",
"phone_number_1",
"phone_area_code_2",
"phone_number_2",
"fax_area_code",
"fax_number",
"email",
"special_status",
"special_status_date"
),
col_types = cols(.default = "c"),
col_select = c(
"cnpj_basic", "cnpj_order", "cnpj_dv",
"street_type", "street_name", "number", "address_complement",
"neighborhood", "postal_code"
),
show_col_types = FALSE
) |>
distinct(cnpj_basic, cnpj_order, cnpj_dv, .keep_all = TRUE)
},
.progress = TRUE
) |>
list_rbind()
#> ■■■■ 10% | ETA: 10m
#> ■■■■■■■ 20% | ETA: 6m
#> ■■■■■■■■■■ 30% | ETA: 4m
#> ■■■■■■■■■■■■■ 40% | ETA: 3m
#> ■■■■■■■■■■■■■■■■ 50% | ETA: 2m
#> ■■■■■■■■■■■■■■■■■■■ 60% | ETA: 2m
#> ■■■■■■■■■■■■■■■■■■■■■■ 70% | ETA: 1m
#> ■■■■■■■■■■■■■■■■■■■■■■■■■ 80% | ETA: 45s
#> ■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 90% | ETA: 22srfb_data |> glimpse()
#> Rows: 9,208,201
#> Columns: 9
#> $ cnpj_basic <chr> "33522741", "30193526", "30943196", "37895692", …
#> $ cnpj_order <chr> "0001", "0001", "0001", "0001", "0001", "0001", …
#> $ cnpj_dv <chr> "91", "04", "19", "93", "35", "12", "56", "91", …
#> $ street_type <chr> "RUA", "RUA", "RUA", "RUA", "QUADRA", "AVENIDA",…
#> $ street_name <chr> "WERNER VON SIEMENS", "PORTO SEGURO", "CARLOS VI…
#> $ number <chr> "111", "1020", "151", "136", "SN", "2099", "31",…
#> $ address_complement <chr> NA, NA, "APT 22", NA, "SALA 906", NA, NA, NA,…
#> $ neighborhood <chr> "LAPA DE BAIXO", "NOVA VISTA", "VILA GUARANI (Z …
#> $ postal_code <chr> "05069900", "31070130", "04307000", "03715070", …Tidy the RFB Data
rfb_data <-
rfb_data |>
mutate(
cnpj_basic = str_pad(cnpj_basic, 8, pad = "0"),
cnpj_order = str_pad(cnpj_order, 4, pad = "0"),
cnpj_dv = str_pad(cnpj_dv, 2, pad = "0"),
cnpj = if_else(
!is.na(cnpj_basic) & !is.na(cnpj_order) & !is.na(cnpj_dv),
paste0(
str_sub(cnpj_basic, 1, 2),
".", str_sub(cnpj_basic, 3, 5),
".", str_sub(cnpj_basic, 6, 8),
"/", cnpj_order,
"-", cnpj_dv
),
NA_character_
)
) |>
select(-cnpj_basic, -cnpj_order, -cnpj_dv) |>
relocate(cnpj)rfb_data |> glimpse()
#> Rows: 9,208,201
#> Columns: 7
#> $ cnpj <chr> "33.522.741/0001-91", "30.193.526/0001-04", "30.…
#> $ street_type <chr> "RUA", "RUA", "RUA", "RUA", "QUADRA", "AVENIDA",…
#> $ street_name <chr> "WERNER VON SIEMENS", "PORTO SEGURO", "CARLOS VI…
#> $ number <chr> "111", "1020", "151", "136", "SN", "2099", "31",…
#> $ address_complement <chr> NA, NA, "APT 22", NA, "SALA 906", NA, NA, NA,…
#> $ neighborhood <chr> "LAPA DE BAIXO", "NOVA VISTA", "VILA GUARANI (Z …
#> $ postal_code <chr> "05069900", "31070130", "04307000", "03715070", …Cross-Reference Data with RFB Data
establishment_data <-
establishment_data |>
left_join(rfb_data, by = "cnpj") |>
relocate(starts_with("locais_nova"), .after = postal_code)establishment_data |> glimpse()
#> Rows: 71,412
#> Columns: 19
#> $ cnpj <chr> "75.315.333/0101-71", "75.315.333/0277-32", "04.…
#> $ cnae <chr> "4711-3/01", "4711-3/01", "4711-3/01", "4711-3/0…
#> $ region_code <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
#> $ region <chr> "North", "North", "North", "North", "North", "No…
#> $ state_code <int> 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, …
#> $ state <chr> "Tocantins", "Tocantins", "Tocantins", "Tocantin…
#> $ federal_unit <chr> "TO", "TO", "TO", "TO", "TO", "TO", "TO", "TO", …
#> $ municipality_code <int> 1721000, 1721000, 1721000, 1721000, 1721000, 172…
#> $ municipality <chr> "Palmas", "Palmas", "Palmas", "Palmas", "Palmas"…
#> $ street_type <chr> NA, "QUADRA", "QUADRA", "AVENIDA", "QUADRA", "QU…
#> $ street_name <chr> NA, "412 SUL AVENIDA NS 10", "1012 SUL ALAMEDA 5…
#> $ number <chr> NA, "S/N", "SN", "S/N", "S/N", "S/N", "S/N", "S/…
#> $ address_complement <chr> NA, "QUADRAASR SE 45 LOTE 06 A 09", "…
#> $ neighborhood <chr> NA, "PLANO DIRETOR SUL", "PLANO DIRETOR SUL", "P…
#> $ postal_code <chr> NA, "77021230", "77023658", "77024546", "7702163…
#> $ locais_nova_g0 <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
#> $ locais_nova_g1_g2 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, …
#> $ locais_nova_g3 <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,…
#> $ locais_nova_g4 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, …Tidy New Addresses
The new addresses obtained from the RFB data are tidied up for consistency.
establishment_data <-
establishment_data |>
rename(complement = address_complement) |>
mutate(
street_type = str_to_title(street_type),
street_name = str_to_title(street_name),
address = if_else(
!is.na(street_type) & !is.na(street_name),
paste(street_type, street_name),
NA_character_
),
number =
number |>
str_remove_all("\\D") |>
str_trim() |>
as.numeric() |>
as.character() |>
suppressWarnings(),
complement = str_to_title(complement),
neighborhood = str_to_title(neighborhood),
postal_code =
postal_code |>
str_remove_all("\\D") |>
str_pad(pad = 0, width = 8),
postal_code = if_else(
!is.na(postal_code),
paste0(
str_sub(postal_code, 1, 5),
"-",
str_sub(postal_code, 6, 8)
),
NA_character_
)
) |>
mutate(
across(
.cols = where(is.character),
.fns = function(x) {
Encoding(x) <- "UTF-8"
iconv(x, from = "", to = "UTF-8", sub = "")
}
)
) |>
relocate(address, .after = municipality) |>
select(-starts_with("street"))establishment_data |> glimpse()
#> Rows: 71,412
#> Columns: 18
#> $ cnpj <chr> "75.315.333/0101-71", "75.315.333/0277-32", "04.4…
#> $ cnae <chr> "4711-3/01", "4711-3/01", "4711-3/01", "4711-3/01…
#> $ region_code <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
#> $ region <chr> "North", "North", "North", "North", "North", "Nor…
#> $ state_code <int> 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, 1…
#> $ state <chr> "Tocantins", "Tocantins", "Tocantins", "Tocantins…
#> $ federal_unit <chr> "TO", "TO", "TO", "TO", "TO", "TO", "TO", "TO", "…
#> $ municipality_code <int> 1721000, 1721000, 1721000, 1721000, 1721000, 1721…
#> $ municipality <chr> "Palmas", "Palmas", "Palmas", "Palmas", "Palmas",…
#> $ address <chr> NA, "Quadra 412 Sul Avenida Ns 10", "Quadra 1012 …
#> $ number <chr> NA, NA, NA, NA, NA, NA, NA, NA, "28", NA, NA, NA,…
#> $ complement <chr> NA, "Quadraasr Se 45 Lote 06 A 09", "L…
#> $ neighborhood <chr> NA, "Plano Diretor Sul", "Plano Diretor Sul", "Pl…
#> $ postal_code <chr> NA, "77021-230", "77023-658", "77024-546", "77021…
#> $ locais_nova_g0 <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ locais_nova_g1_g2 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, T…
#> $ locais_nova_g3 <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
#> $ locais_nova_g4 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, T…Geocode the Data
fields <- definir_campos(
estado = "federal_unit",
municipio = "municipality_code",
logradouro = "address",
numero = "number",
cep = "postal_code",
localidade = "neighborhood"
)establishment_data <-
establishment_data |>
geocode(
campos_endereco = fields,
resultado_sf = FALSE,
verboso = TRUE,
cache = TRUE,
n_cores = 4,
resolver_empates = TRUE
)
#> ℹ Padronizando endereços de entrada
#> ℹ Utilizando dados do CNEFE armazenados localmente
#> ℹ Geolocalizando endereços
#> Endereços processados: 0/71,412 ■ 0% - Proc…
#>
#> Endereços processados: 17,554/71,412 ■■■■■■■■ 25% -…
#>
#> Endereços processados: 30,397/71,412 ■■■■■■■■■■■■■■ 43% -…
#>
#> Endereços processados: 31,294/71,412 ■■■■■■■■■■■■■■ 44% -…
#>
#> Endereços processados: 32,284/71,412 ■■■■■■■■■■■■■■■ 45% -…
#>
#> Endereços processados: 42,819/71,412 ■■■■■■■■■■■■■■■■■■■ 60% -…
#>
#> Endereços processados: 48,426/71,412 ■■■■■■■■■■■■■■■■■■■■■ 68% -…
#>
#> Endereços processados: 48,932/71,412 ■■■■■■■■■■■■■■■■■■■■■■ 69% -…
#>
#> Endereços processados: 49,432/71,412 ■■■■■■■■■■■■■■■■■■■■■■ 69% -…
#>
#> Endereços processados: 50,776/71,412 ■■■■■■■■■■■■■■■■■■■■■■ 71% -…
#>
#> Endereços processados: 51,655/71,412 ■■■■■■■■■■■■■■■■■■■■■■■ 72% -…
#>
#> Endereços processados: 51,756/71,412 ■■■■■■■■■■■■■■■■■■■■■■■ 72% -…
#>
#> Endereços processados: 52,014/71,412 ■■■■■■■■■■■■■■■■■■■■■■■ 73% -…
#>
#> Endereços processados: 52,601/71,412 ■■■■■■■■■■■■■■■■■■■■■■■ 74% -…
#>
#> Endereços processados: 53,238/71,412 ■■■■■■■■■■■■■■■■■■■■■■■ 75% -…
#>
#> Endereços processados: 53,822/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■ 75% -…
#>
#> Endereços processados: 54,047/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■ 76% -…
#>
#> Endereços processados: 54,432/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■ 76% -…
#>
#> Endereços processados: 54,473/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■ 76% -…
#>
#> Endereços processados: 54,510/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■ 76% -…
#>
#> Endereços processados: 54,531/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■ 76% -…
#>
#> Endereços processados: 54,608/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■ 76% -…
#>
#> Endereços processados: 59,588/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■■■ 83% -…
#>
#> Endereços processados: 66,535/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 93% -…
#>
#> Endereços processados: 67,603/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 95% -…
#>
#> Endereços processados: 71,412/71,412 ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■ 100% -…
#>
#>
#>
#> ℹ Preparando resultados
#> Foram encontrados e resolvidos 1954 casos de empate.establishment_data <-
establishment_data |>
as_tibble() |>
rename(
latitude = lat,
longitude = lon,
geocodebr_precision = precisao,
geocodebr_type_of_result = tipo_resultado,
geocodebr_deviation_meters = desvio_metros,
geocodebr_address_found = endereco_encontrado,
geocodebr_ambiguous = empate
) |>
relocate(starts_with("locais_nova"), .after = geocodebr_ambiguous) |>
drop_na(all_of(c("latitude", "longitude")))establishment_data |> glimpse()
#> Rows: 71,412
#> Columns: 25
#> $ cnpj <chr> "75.315.333/0101-71", "75.315.333/0277-3…
#> $ cnae <chr> "4711-3/01", "4711-3/01", "4711-3/01", "…
#> $ region_code <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
#> $ region <chr> "North", "North", "North", "North", "Nor…
#> $ state_code <int> 17, 17, 17, 17, 17, 17, 17, 17, 17, 17, …
#> $ state <chr> "Tocantins", "Tocantins", "Tocantins", "…
#> $ federal_unit <chr> "TO", "TO", "TO", "TO", "TO", "TO", "TO"…
#> $ municipality_code <int> 1721000, 1721000, 1721000, 1721000, 1721…
#> $ municipality <chr> "Palmas", "Palmas", "Palmas", "Palmas", …
#> $ address <chr> NA, "Quadra 412 Sul Avenida Ns 10", "Qua…
#> $ number <chr> NA, NA, NA, NA, NA, NA, NA, NA, "28", NA…
#> $ complement <chr> NA, "Quadraasr Se 45 Lote 06 …
#> $ neighborhood <chr> NA, "Plano Diretor Sul", "Plano Diretor …
#> $ postal_code <chr> NA, "77021-230", "77023-658", "77024-546…
#> $ latitude <dbl> -10.25185979, -10.25147969, -10.24655266…
#> $ longitude <dbl> -48.32112949, -48.36765397, -48.31424751…
#> $ geocodebr_precision <chr> "municipio", "localidade", "cep", "cep",…
#> $ geocodebr_type_of_result <chr> "dm01", "db01", "dc02", "dc02", "dc02", …
#> $ geocodebr_deviation_meters <int> 13566, 3172, 59, 166, 6, 6, 258, 2550, 8…
#> $ geocodebr_address_found <chr> "PALMAS - TO", "PLANO DIRETOR SUL, PALMA…
#> $ geocodebr_ambiguous <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ locais_nova_g0 <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ locais_nova_g1_g2 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE…
#> $ locais_nova_g3 <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE…
#> $ locais_nova_g4 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE…Visualize Geocoding Precision
establishment_data |>
ggplot(aes(geocodebr_precision)) +
geom_bar(fill = get_brand_color("blue")) +
labs(
x = "{geocodebr} Precision",
y = "Frequency"
)
Data Dictionary
metadata <-
establishment_data |>
`var_label<-`(
list(
cnpj = "CNPJ number",
cnae = "Primary activity CNAE",
region_code = "IBGE region code",
region = "Region name",
state_code = "IBGE state code",
state = "State name",
federal_unit = "Federal unit abbreviation",
municipality_code = "IBGE municipality code",
municipality = "Municipality name",
address = "Street address",
number = "Address number",
complement = "Address complement",
neighborhood = "Neighborhood",
postal_code = "Postal code",
latitude = "Latitude",
longitude = "Longitude",
geocodebr_precision = "{geocodebr} precision value",
geocodebr_type_of_result = "{geocodebr} result type",
geocodebr_deviation_meters = "{geocodebr} deviation (meters)",
geocodebr_address_found = "{geocodebr} address returned",
geocodebr_ambiguous = "{geocodebr} ambiguous result",
locais_nova_g0 = "Locais-Nova Group 0 indicator",
locais_nova_g1_g2 = "Locais-Nova Groups 1 and 2 indicator",
locais_nova_g3 = "Locais-Nova Group 3 indicator",
locais_nova_g4 = "Locais-Nova Group 4 indicator"
)
) |>
generate_dictionary(details = "full") |>
convert_list_columns_to_character()metadataestablishment_dataSave the Valid Data
The processed data are available in csv, rds and parquet formats through a dedicated repository on the Open Science Framework (OSF). See the Data Availability section for more information.
Clean Old Data Files
if (dir_exists(data_dir)) {
dir_delete(data_dir)
dir_create(data_dir, recurse = TRUE)
}Write Data
valid_file_pattern <- "2022"establishment_data |>
write_parquet(
here(data_dir, paste0(valid_file_pattern, ".parquet"))
)Lock Data
Write Metadata
metadata_file_pattern <- paste0(
"2022",
"-",
"metadata"
)Visualize Geocoding
for (i in municipalities) {
# Set Shape -----
shape <-
i |>
read_municipality(
year = closest_geobr_year(year, verbose = FALSE),
showProgress = FALSE
) |>
st_transform(st_crs(4326)) |>
suppressMessages()
# Prepare Data -----
plot_data <-
establishment_data |>
filter(municipality_code == i) |>
pivot_longer(
cols = all_of(
c(
"locais_nova_g0", "locais_nova_g1_g2", "locais_nova_g3",
"locais_nova_g4"
)
),
names_to = "group",
values_to = "value"
) |>
filter(value == TRUE) |>
st_as_sf(
coords = c("longitude", "latitude"),
crs = 4326
) |>
st_join(shape, join = st_within, left = FALSE) %>%
mutate(
latitude = st_coordinates(.)[,2],
longitude = st_coordinates(.)[,1]
) |>
st_drop_geometry() |>
transmute(
group =
group |>
str_remove("locais_nova_") |>
str_to_upper() |>
str_replace("_", "-"),
latitude,
longitude
)
# Plot Data ---
plot <-
ggplot() +
geom_sf(
data = shape,
fill = "gray90",
color = "black"
) +
geom_point(
data = plot_data,
mapping = aes(x = longitude, y = latitude, color = group),
size = 0.01
) +
facet_wrap(~ group, ncol = 4) +
coord_sf(crs = 4326) +
scale_x_continuous(labels = NULL, breaks = NULL) +
scale_y_continuous(labels = NULL, breaks = NULL) +
scale_colour_brand_d() +
theme(legend.position = "none") +
labs(
title = paste(
"Locais-Nova Establishments in",
municipalities_data |>
filter(municipality_code == i) |>
pull(municipality)
),
x = NULL,
y = NULL,
color = NULL,
caption =
paste0(
"Source: ",
"Brazilian Federal Revenue Service (RFB), as of ",
month.name[month], " ",
year,
"."
)
)
print(plot)
}
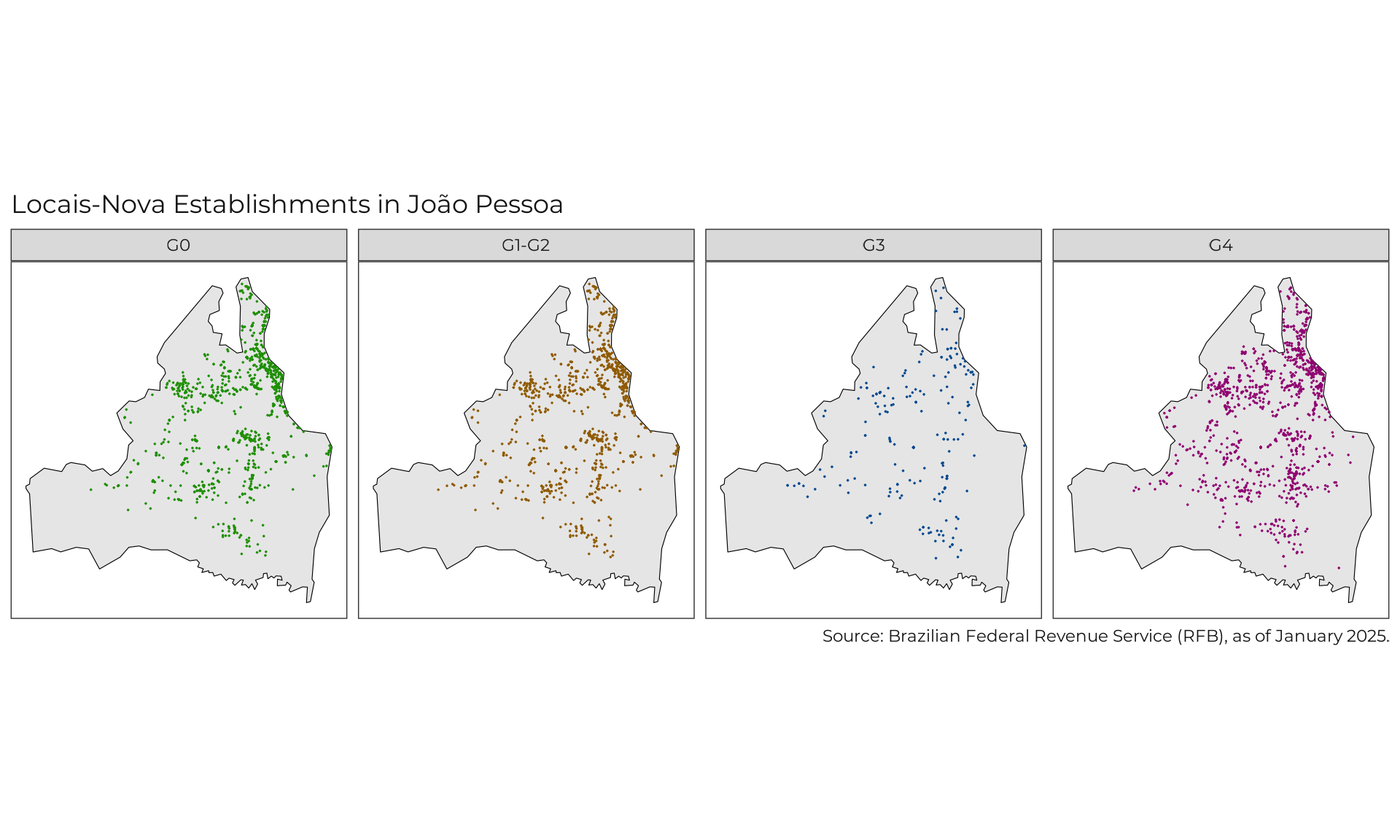

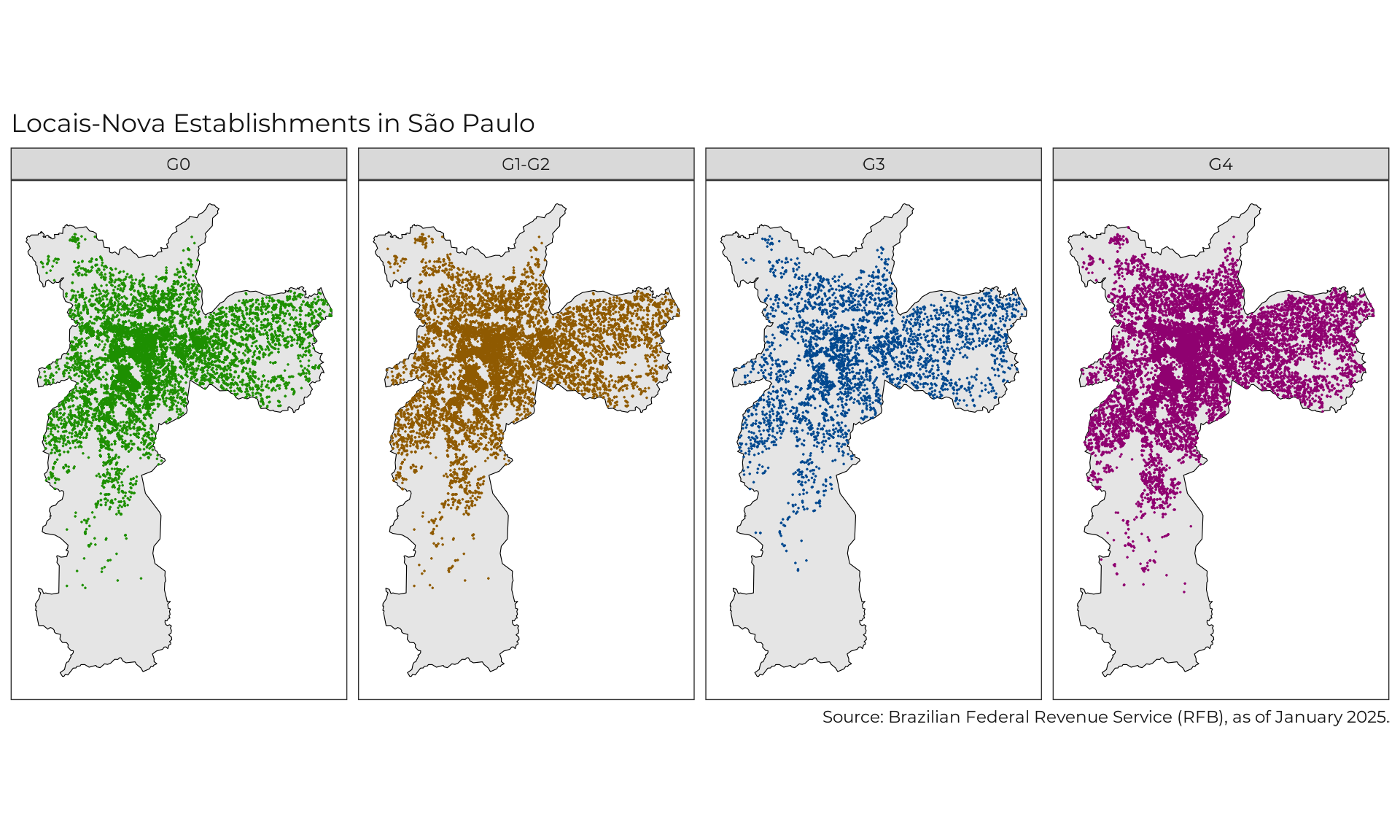
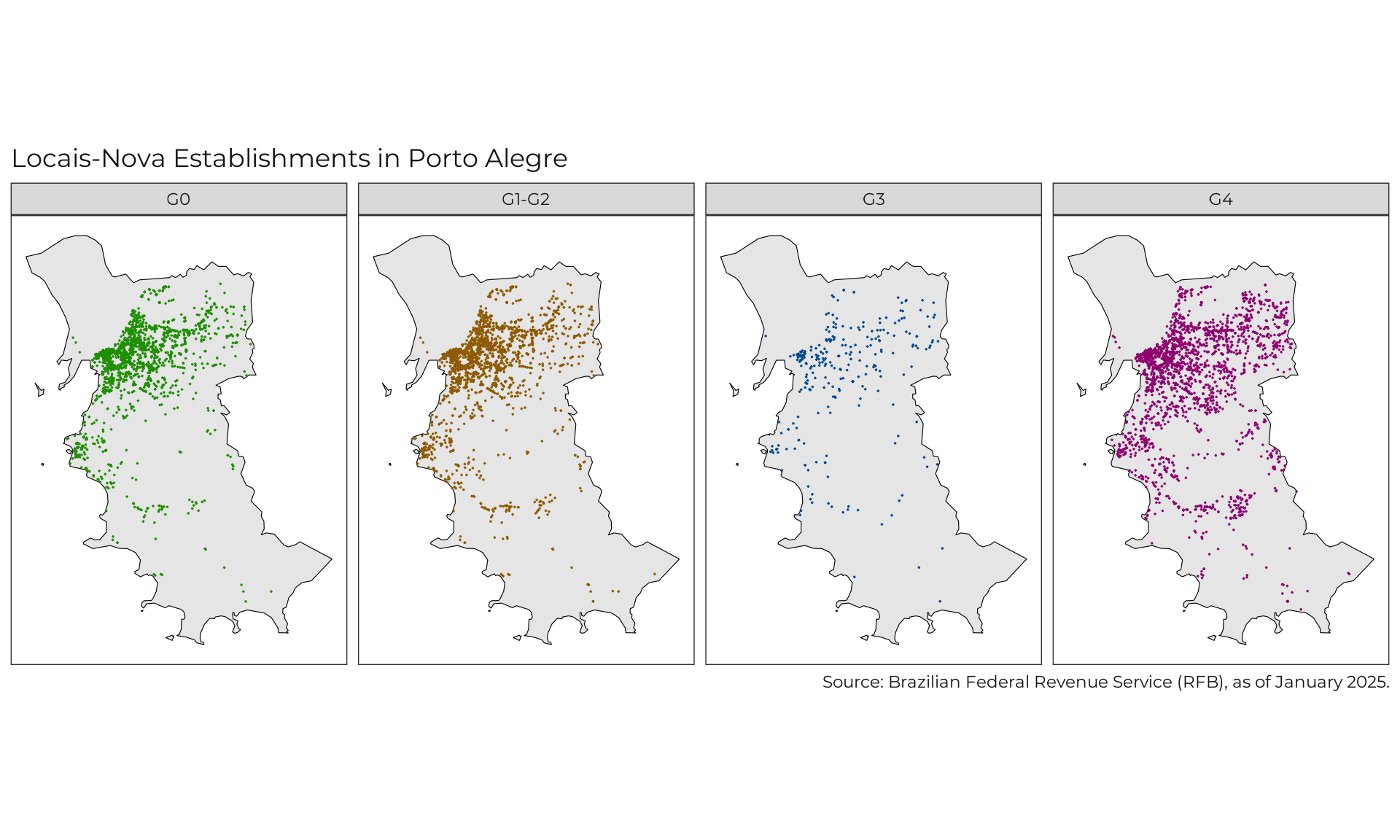
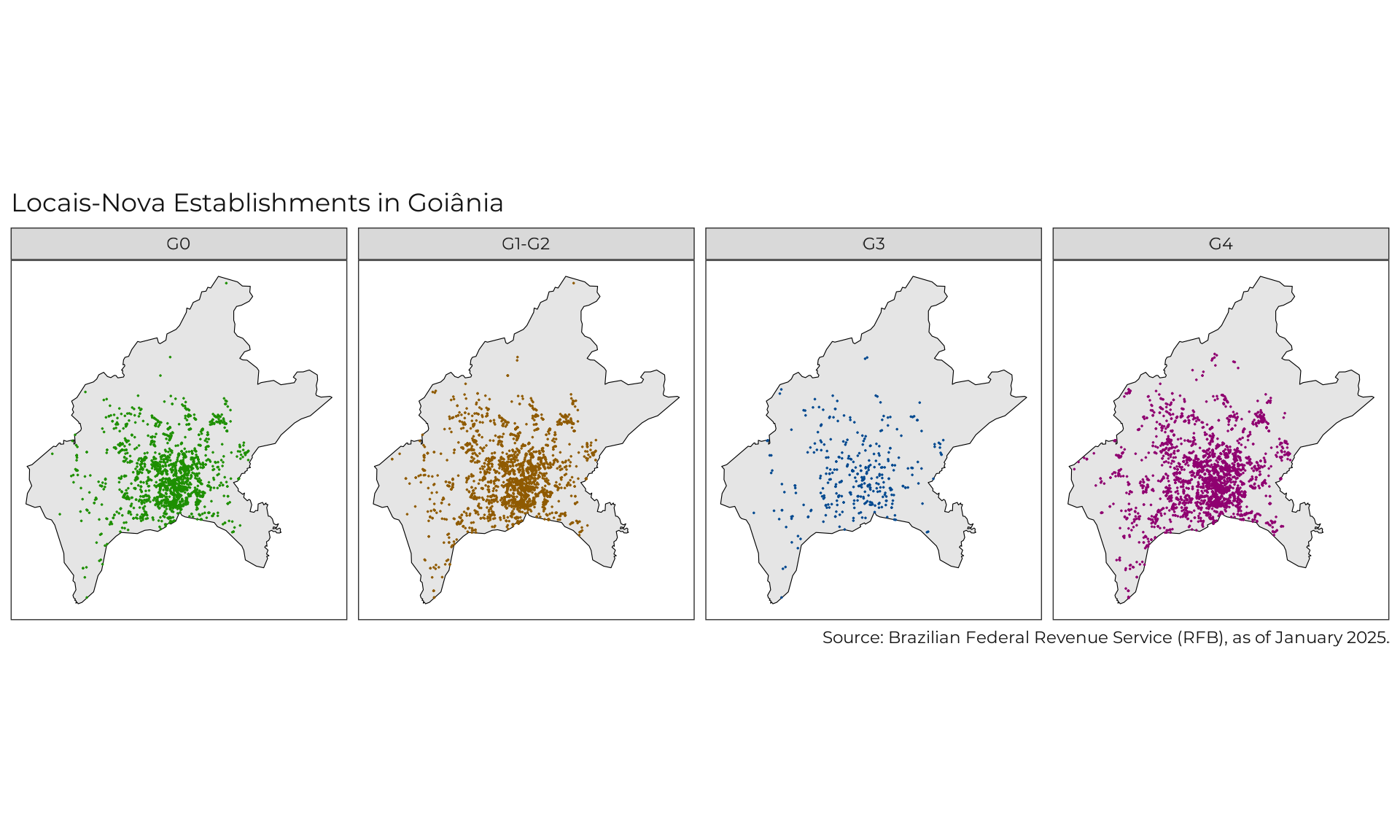

Citation
When using this data, you must also cite the original data sources.
To cite this work, please use the following format:
Caldeira, G., Penz, C., Vartanian, D., Fernandes, C. N., & Giannotti, M. A. (2025). A reproducible pipeline for processing, geocoding, and classifying CNPJs from the Annual Social Information Report (RAIS) of the Brazilian Ministry of Labor and Employment (MTE) using the Locais-Nova scale [Computer software]. Center for Metropolitan Studies of the University of São Paulo. https://cem-usp.github.io/locais-nova-rais-geocoding
A BibLaTeX entry for LaTeX users is:
@software{caldeira2025,
title = {A reproducible pipeline for processing, geocoding, and classifying CNPJs from the Annual Social Information Report (RAIS) of the Brazilian Ministry of Labor and Employment (MTE) using the Locais-Nova scale},
author = {{Gabriel Caldeira} and {Clara Penz} and {Daniel Vartanian} and {Camila Nastari Fernandes} and {Mariana Abrantes Giannotti}},
year = {2025},
address = {São Paulo},
institution = {Center for Metropolitan Studies of the University of São Paulo},
langid = {en},
url = {https://cem-usp.github.io/locais-nova-rais-geocoding}
}License
![]()
![]()
The original data sources may be subject to their own licensing terms and conditions.
The code in this report is licensed under the GNU General Public License Version 3, while the report is available under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International.
Copyright (C) 2025 Center for Metropolitan Studies
The code in this report is free software: you can redistribute it and/or
modify it under the terms of the GNU General Public License as published by the
Free Software Foundation, either version 3 of the License, or (at your option)
any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY
WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with
this program. If not, see <https://www.gnu.org/licenses/>.Acknowledgments
This work is part of a research project by the Polytechnic School (Poli) of the University of São Paulo (USP), in partnership with the Secretariat for Food and Nutrition Security (SESAN) of the Ministry of Social Development, Family, and the Fight Against Hunger (MDS), titled: AcessoSAN: Mapping Food Access to Support Public Policies on Food and Nutrition Security and Hunger Reduction in Brazilian Cities.
This study was financed, in part, by the São Paulo Research Foundation (FAPESP), Brazil. Process Number 2025/17879-2.
References
Aho, A., Kernighan, B., & Weinberger, P. (2023). The AWK programming language. Addison-Wesley Professional. https://www.awk.dev
R Core Team. (n.d.). R: A language and environment for statistical computing [Computer software]. R Foundation for Statistical Computing. https://www.R-project.org
Ushey, K., & Wickham, H. (n.d.). renv: Project environments [Computer software]. https://doi.org/10.32614/CRAN.package.renv
Wickham, H. (2023). The tidy tools manifesto. Tidyverse. https://tidyverse.tidyverse.org/articles/manifesto.html
Wickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for data science: Import, tidy, transform, visualize, and model data (2nd ed.). O’Reilly Media. https://r4ds.hadley.nz